



多目标优化和多任务学习的区别是什么?
更新时间:2024-06-18 21:14:15
我看了一圈答案好像部分人认为这俩是一个东西,但是看@王源大佬的这篇回答这俩好像又是不同的领域NIPS 2018 有什么值得关注的亮点?
那么到底他们之间的区别是什么,难道真的只是learning和opertimization的区别吗
额外的,multi-task和multi-view之间是否有联系和区别呢
我觉得完全没关系的吧。
多目标优化同时优化多个函数,想办法得到帕累托最优
多任务学习迁移学习一部分,一个网络一部分公用,之后多个分支做不同任务
我觉得“多目标模型”和“多任务模型”的区别,两者的差异点的关键在于“任务”的定义,一个“任务”其实是包含了“任务数据集”和“任务目标”,就是由多个X到多个Y,多任务其实说的是依赖于多个数据集及其任务目标,进行相互辅助学习(但不追求同时,所以概念贴近于迁移学习),而多目标模型是使用同一个数据源,但是要同时输出Y的集合。
比较特殊的,其实完全也可以利用 迁移学习/多任务学习 来做多目标模型,比如A项目组的多目标模型通过一定的方式,B项目组拿去用,这时候如果找到一个机制,同时学习A、B项目组的任务,那这就成了使“多(多目标)任务学习“。
最近在找相关资料,按照自己的理解回答一波:
多目标优化是优化(遗传算法优化,进化算法优化等等),多任务学习是学习(机器学习,深度学习),多目标优化可以去优化多任务学习的某个部分(比如多个任务之间的权衡).多目标优化可以用在很多地方,不一定跟学习结合.
多目标系列
- 多目标 | 概览
- 多目标 | 模型结构: ESMM从目标关系出发
- 多目标 | 模型结构: ESM2细化目标依赖路径
- 多目标 | 模型结构: MMoE开辟结构新方向
- 多目标 | 模型结构: MMoE实际应用,理论和实践是两回事
- 多目标 | 模型结构: PLE显式细化expert表征
本文分享AAAI2023的一篇论文,FDN,用于解决多目标中的负迁移问题。
FDN(Feature Decomposition Network)[1]出自论文
《Feature Decomposition for Reducing Negative Transfer: A Novel Multi-task Learning Method for Recommender System》
核心思路是通过引入约束,对task依赖的特征表征进行分解,使task的共性和特性进行更准确的学习,从而缓解多任务学习的负迁移问题。
前面几篇分享《多目标 | 模型结构: MMoE开辟结构新方向》《多目标 | 模型结构: PLE显式细化expert表征》多次提到多目标学习的难点在于task的关系复杂,存在拉扯问题,导致负迁移和跷跷板现象。针对负迁移的问题,MMoE将bottom拆分为多个expert,不同的task对expert自适应组合;PLE在MMoE的基础上,进一步对expert细化,将其拆分为task共享和task独有两部分进行学习。
这两种方法在一定程度上可以缓解task之间的拉扯,但由于task对expert的学习是通过gate自适应的方式,使得expert在学习特征表征时受到的约束弱,仅来自task的损失约束,因此很难使expert的特征表征达到理想状态,即不同expert学不同子空间的表征,有效区分task共性和特性。
理想情况下,多目标模型中不同task依赖的特征表达包括共享和独有两部分,这两部分来自不同的子空间,区分度明显,如图1右图所示。实际模型在学习过程中,容易陷入“偷懒”状态,难以达到理想情况,而是处于一个中间状态,即共享和独有两部分的特征表征的子空间存在交叉,不完全独立,如图1左图所示。
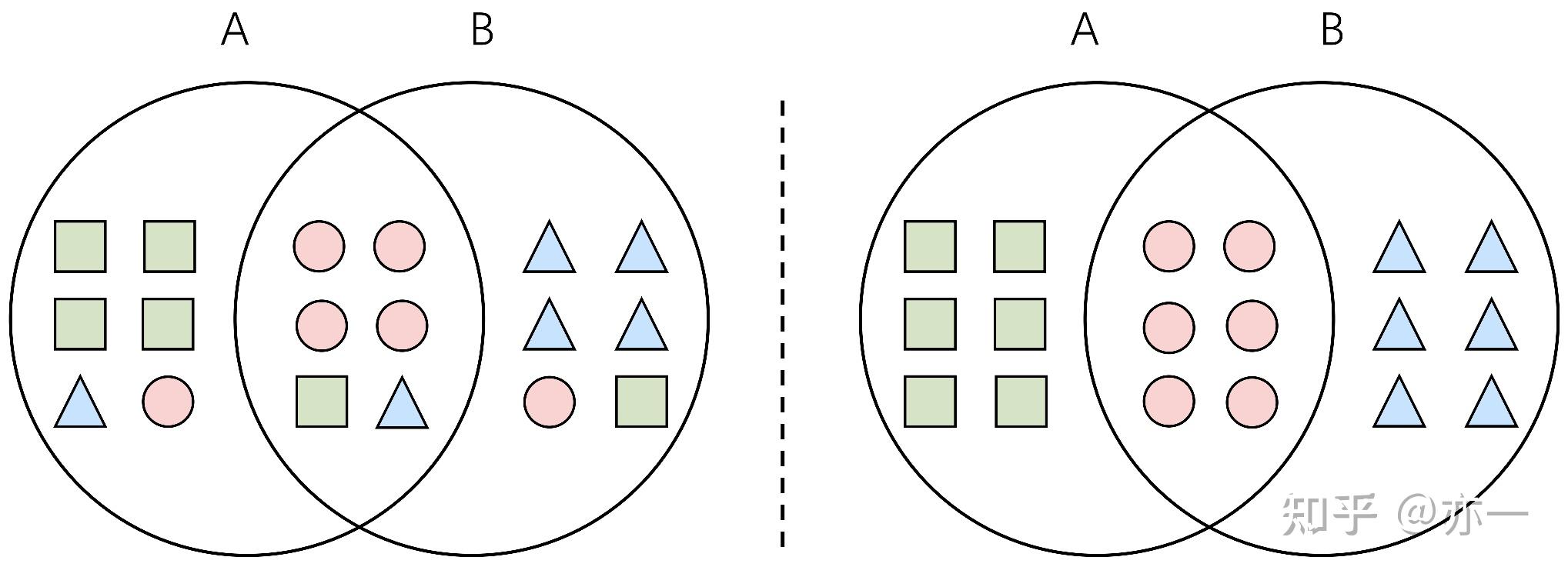
为了降低特征表征的冗余问题,FDN采用特征分解的方式,将其分解为task共享和task独有两部分,并在特征表征学习过程中引入更强的约束,降低两者的交叉性,降低不同task中特征表征的噪音,从而提高输入到task中的特征表征的质量和效果。
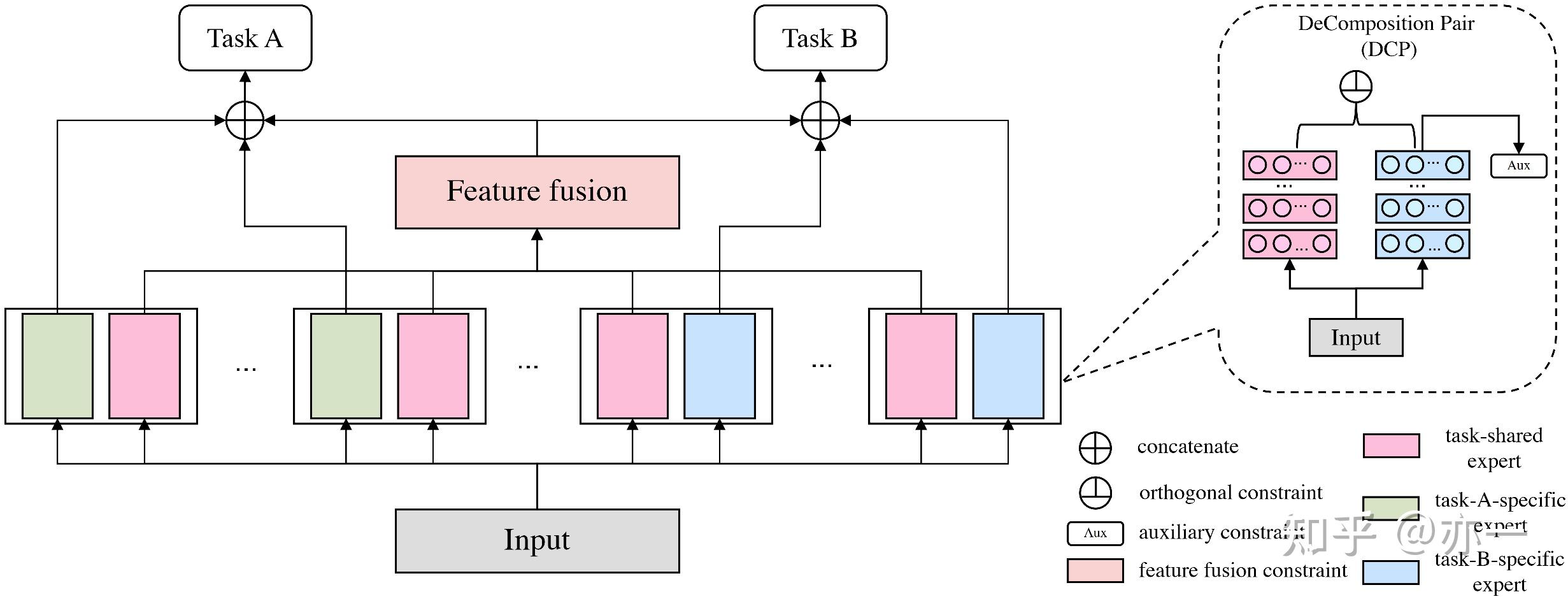
FDN在模型结构上沿用多目标模型的整体框架,在底层bottom部分对特征分解,进行特征抽取,再将提取到的特征按照一定的方式组合后输入到不同的task中。
为了提高特征分解的学习效果,FDN引入了正交和辅助task等约束,使task共享和task独有的特征表征更聚焦,降低冗余和噪音,提高表征的质量。
FDN的模型结构整体类似CGC结构,包括bottom、特征组合和task几部分,如图2所示,其中bottom部分进行特征分解,对每个task采用单组或多组分解对(DeComposition Pair,简写为DCP),每组分解对包括task共享和task独有两种特征表征,在特征组合部分对task共享和task独有两部分进行组合,得到task的输入,进行后续task部分的学习。
模型对每个task的学习可以表示为式子(1),其中task的输入由共享和独有两种特征表征组合, 表示某个task DCP中task共享的特征表征,
表示task独有的特征表征,
表示task K对特征表征的组合方式,
为激活函数。
FDN在bottom部分通过特征分解的方式,人为先验地在特征表征层面强化了task共性和task特性的差异,但模型在学习过程中,受限于监督信号的强度,未必能将不同的信息学到不同的表征中,因此为了更好地达到特征分解的目的,使不同特征表征的子空间更“纯净”、区分度更强,对特征表征的学习引入新的约束:特征表征正交约束、辅助task约束和task共享表征融合约束。
2.2.1 特征表征正交
正交约束目的是使每个task的DCP中共享和独有两种特征表征尽可能差异化,从而提高模型对各个task之间的共性和差异性的捕捉能力。
正交约束的计算如式子(2)所示,其中K表示task的数量,M表示task k的特征分解对(DCP)数量, 表示task k的第m个task共享的特征表征,
表示task k的第m个task独有的特征表征,
为Frobenius范数,这个范数是针对矩阵而言的,可以类比向量的L2范数,其计算是对矩阵中每个元求平方和后开方。
2.2.2 辅助task
正交约束可以加强两种特征表征的正交性,而正交的维度可以有非常多,无法保证两者是task共享和task独有这个维度的正交,因此引入辅助task约束,使task的DCP中两种表征,不仅仅只是理论含义上的“共享”和"独立",而是实际上也学到这两种子空间上。
对每个task而言,将DCP中task独立的特征表征看成是该task特征抽取的单独小网络,因此用这部分的特征表征进行task预估,作为辅助task。将辅助task的损失作为task独有特征表征学习的约束,可以使这部分表征聚焦于学习task的特性,再结合正交约束和主loss的约束,task共享特征表征则可以聚焦到task共性的捕捉上。
辅助task约束如式子(3)所示,其中 为task k的辅助loss函数,可以选择和主loss保持一致,
为task k的真实标签,
为task k中第m个独有特征表征的task预估,计算如式子(4)所示。
2.2.3 task共享表征融合
所有task的共享表征融合后,得到一个整体的共享表征,各个task将其和task各自独有的表征concat,得到task的输入。这个过程中,共享表征的融合操作,可以看作是对各个task共享表征的约束,即把各个task的共享表征的学习约束到同一个子空间。
相比于对所有task学习一个共享表征,这种方式通过各个task的共享表征而后融合,可以达到在同一空间中,学到更丰富的表达的效果。
2.2.4 整体损失
FDN整体的损失包括task的主loss,特征表征正交loss和辅助task loss三部分,如式子(5)所示。
相比于多目标学习中的其它方法,如MMoE、PLE等,FDN特征分解的思路,和CGC\\PLE没有本质区别,都是分解为task共享和task独有两部分,其中微小的差异在于,FDN中每个task有对应的task共享部分,而CGC/PLE中,task共享部分是一个整体,所有task参数共享。
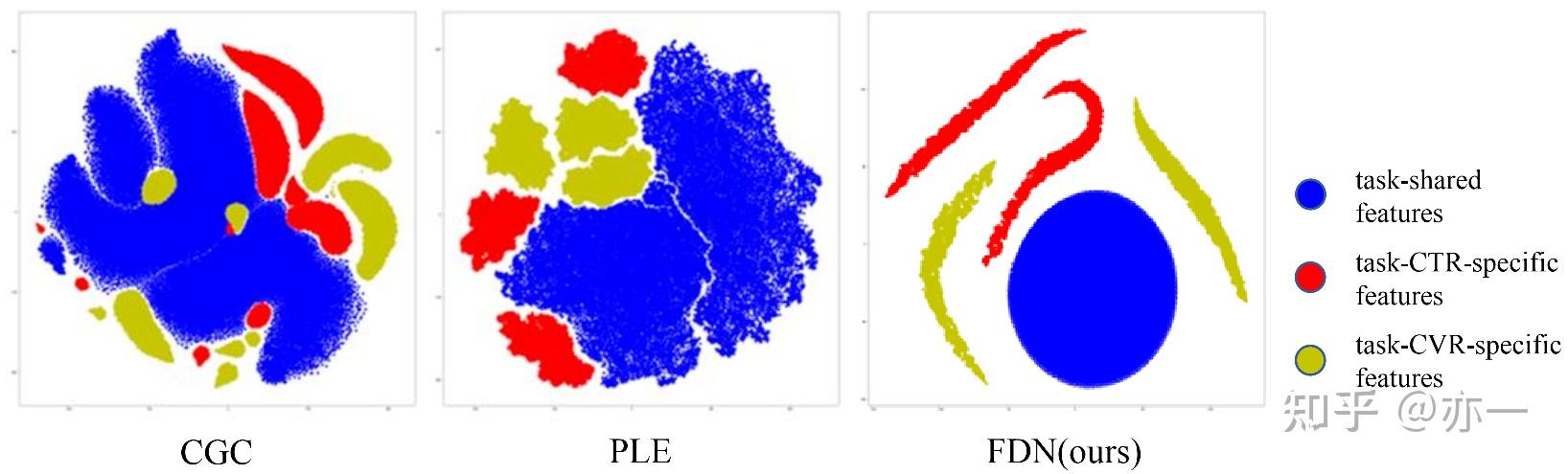
FDN的核心改进在于加强了对特征表征的约束,使其可以更符合设计初衷去抽取特征。当只有主loss约束时,特征表征虽然在形式上进行了分解,但实际学到的可能存在交叉,区分度有待提高。论文对CGC、PLE和FDN三种方法的特征表征进行了可视化,如图3所示,可以看出,通过加入更多的约束,task共享和task独有两种特征表征的区分度和差异化明显提升。
模型的学习是一个复杂的过程,但有一点可以肯定,模型的学习效果和它收到的监督信号密切相关,当发现模型某些方面表现不如预期,可以借鉴FDN中加强约束的方式,引入更强的监督信号,改善模型的学习过程。
FDN的落地并不复杂,主要的代码调整是对特征表征的融合,以及新加几种loss。
论文中仅对bottom中最后一层中两种特征表征使用了正交loss,为了加强这两种表征的正交性,可以考虑在每一层都对两者进行正交约束,如式子(6)所示,其中H表示bottom中特征抽取的层数。 正交loss使用的是针对矩阵的Frobenius范数,这里可以考虑适当的简化,即用向量之间的范数。这里的简化可以从两方面出发:
- (1) Frobenius范数计算量大,实际训练中资源消耗大;
- (2) 向量之间计算范数,实际物理含义是两个向量的正交性,采用Frobenius范数对向量A和向量B进行计算,相当于向量A中每个元素和向量B计算一次代价,这种计算是否有实际物理含义,值得商榷。
FDN对每个task进行了共享和独有的特征分解,因此容易带来模型容量的增加,在实际对比效果时,需在同样的模型容量下进行,才能说明效果是方法上的改进带来的,而非模型容量增加带来的。
推荐系列文章:
工作相关的内容会更新在【播播笔记】公众号,欢迎关注

生活的思考和记录会更新在【吾之】公众号,欢迎关注

reference
[1]Feature Decomposition for Reducing Negative Transfer: A Novel Multi-task Learning Method for Recommender System. Feature Decomposition for Reducing Negative Transfer: A Novel Multi-task Learning Method for Recommender System
最直白的说、最简单的区别:
优化的三个要素:目标f(x);约束;变量x。
多目标优化,找同一套x,同时优化f1(x),f2(x)…
多任务优化(学习),找多套x1,x2…,分别优化f1(x1),f2(x2)…

