



自用Pytorch笔记(十五:防止过拟合的几种方法)(1.1版本)
更新时间:2024-07-22 07:42:35
一、使用正则项
1、L2 Regularization
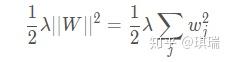
只要直接在训练前为optimizer设置正则化项的λ \\lambdaλ参数(这里不叫Regularization而是用了Weight Decay这个叫法):
正则化项目是用来克服over-fitting的,如果网络本身就没有发生over-fitting,那么设置了正则化项势必会导致网络的表达能力不足,引起网络的performance变差。
2、若使用L1正则化项,即对所有参数绝对值求和再乘以一个系数:
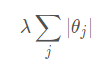
在PyTorch中还没有直接设置L1 范数的方法,可以在训练时Loss做BP之前(也就是.backward()之前)手动为Loss 加上L1范数:
# 为Loss添加L1正则化项
L1_reg=0
for param in net.parameters():
L1_reg +=torch.sum(torch.abs(param))
loss +=0.001 * L1_reg # lambda=0.001用上节的代码试了一下,使用L1正则化项时如果指定和使用L2 正则化项时相同的λ=0.01 会发生under-fitting,似乎如果要用L1 正则化的话要把其系数设置的小一点,所以这里用了0.001。
二、动量(momentum)
之前学习的用梯度更新参数w的公式:
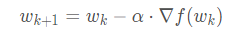
其中α 是学习率。
现改用
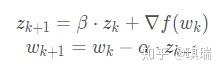
来代替。即相当于原式子又减去了一个α?β?Zk这一项。其中z表征了上次更新的方向和大小,而?f(w) 则是梯度,所以新的式子综合考虑了梯度下降的方向和上次更新的方向,用β来决定了惯性的大小。
优点:
(1)不仅考虑了当前的梯度下降的方向,还综合考虑了上次更新的情况,使得学习器学习过程的幅度和角度不会太尖锐,特别是遇到来回抖动的情况时大有好转。
(2)当遇到局部极小值时,因为设置了惯性,所以可能可以冲出局部最小值,这样就更可能找到一个全局最小值。
使用方法:
某些优化器(如Adam)内置了momentum,所以没有这个参数,对多数优化器直接设置就可以了,传进去的参数是β 的取值。其取值越大则考虑之前的更新方向的程度就越大,取值为0时即相当于没有惯性。
optimizer=optim.SGD(net.parameters(), lr=learning_rate, momentum=0.78)
三、Learning Rate Decay
在使用梯度更新参数时,学习率如果选取太小的话,学习过程会很慢;如果学习率选取太大,那么很可能会出现来回抖动的情况,这时最终的模型可能很难收敛,而且看起来和"梯度弥散"的情况也很像(但其实不是)。
选取合适的固定的学习率是很难的, 可以在训练的一开始选取比较大的学习率加快训练过程,然后逐渐让其衰减到比较小的值,最终让模型收敛。
(1)ReduceLROnPlateau
Plateau是平原的意思,这个类即用来监控某个量,当其在训练过程中多次没有发生下降(或上升,取决于mode参数)时,就减少学习率。首先,在定义优化器时:
from torch.optim.lr_scheduler import ReduceLROnPlateau
optimizer=......
# 传入优化器让学习率受其管理,当连续200次没有减少loss时就会减少学习率(乘以0.7)
scheduler=ReduceLROnPlateau(optimizer, mode="min", patience=200, factor=0.7)在每次训练时,改用这个scheduler来执行.step()方法,并传入要监控的量,这里即是传入计算出的loss:
optimizer.step()
# 传入要监控的量,每调用一次step就会监控一次loss
# 前面定义时的mode="min"即是监控量没有减少时触发减小lr的操作的
scheduler.step(loss)(2)StepLR
这个就和监控量没关系了,是固定的每执行step_size个.step()方法,就把学习率乘以gamma即可。
定义优化器时:
from torch.optim.lr_scheduler import StepLR
optimizer=......
# 每跑800个step就把学习率乘以0.9
scheduler=StepLR(optimizer, step_size=800, gamma=0.9)训练时(注意不用传监控量进去了):
optimizer.step()
scheduler.step()
三、Early Stop
如果一直训练,训练集上的性能可以一直上升,但验证集上的性能在经过某个点之后就可能开始下降,这时就是模型出现了over-fitting,提前停止就是用来克服over-fitting的。
但是没训练完怎么知道哪个点是最大值点呢?可以用经验来判断,比如当连续多个epoch上的验证集Acc.在下降时就停止训练。
四、Dropout
为每个连接设置一个probability的属性,以这个概率让其暂时输出0给后面的神经元。即每次forward时每个连接都有一定的概率断开,这样在训练时每次用到的有效的参数量会比不用Dropout时少一些。
使用:在PyTorch中直接在要加的有连接的相邻两层之间插入Dropout层:
self.model=nn.Sequential(
nn.Linear(784, 200),
nn.Dropout(0.5), # 以0.5的概率断开
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.Dropout(0.5), # 以0.5的概率断开
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)在train时,模型使用前指明模式:
# 指明使用"训练用"的网络模式,这里的目的是开启使用Dropout
net.train()
logits=net(data)
loss=......
在validation或者test时,模型使用前指明模式:
# 在验证集上需要把Dropout去掉,只在训练的时候使用!这里是切换一下模式
net.eval()
logits=net(data)
test_loss +=......
注意,如上面这样的定义方式是在logit和非线性激活的直连上做了Dropout,而不是在线性模型层内部做了Dropout。
注意,PyTorch中torch.nn.Dropout()传入的参数是断开的概率,而TensorFlow中tf.nn.dropout()传入的参数是保持连接的概率,即1-断开的概率。
五、Stochastic Gradient Descent
SGD是从训练集中随机选出一个比较小的batch(16/32/64/128…甚至可能只有一个样本)出来,在这个小的样本集上用梯度的均值做梯度下降更新参数。而传统的梯度下降则是每次都要考虑在整个训练集上所有样本的梯度。
使用SGD的原因是训练集样本可能非常多,一方面显存不够把所有样本读进来,另一方面对所有样本计算梯度速度可能太慢了。所以在实际用的时候都不用原始的GD,而是用SGD来做的:
from torch import optim
optimizer=optim.SGD(net.parameters(), lr=learning_rate, momentum=0.78)
原文:https://blog.csdn.net/SHU15121856/article/details/88827238

